Übung zu Inferenzstatistik
Zur Vorbereitung
ESS8-Datensatz einlesen:
Working directory setzen (z.B. "C:/daten")
setwd("mein_laufwerk/mein_datenverzeichnis")
# Daten einlesen
library(haven)
ess8 <- read_dta("ESS8e02_2.dta")- Erstellt ein neues Übungsskript und beschriftet es entsprechend.
# Statistik 2: R Tutorat
# Übungsskript zum Thema Inferenzstatistik
# Datum: 11.05.2021
# AutorIn: XXX- Installiert das Package tidyverse und aktiviert es. Ladet den ESS-Datensatz ein.
# install.packages("tidyverse")
library(tidyverse)
library(ggplot2)
library(labelled)
library(ggeffects)
I.Null- und Alternativhypothese, Standardfehler, p-Wert
1. Wir interessieren uns für den Zusammenhang zwischen Bildung und Migrationswertschätzung. Formuliere dazu eine empirisch prüfbare Hypothese. Wir haben uns bereits in der letzten Übung zum Thema Linearität und Ausreisser Linearität und Ausreisser mit diesen Variablen für die Schweiz auseinandergesetzt. In der folgenden Übung werden wir dies nochmals tun, allerdings nun mit den Merkmalsträgern aus Deutschland.
Forschungshypothese: Je mehr Bildung eine Person hat, desto positiver ist sie gegenüber der Migration eingestellt.
2. Formuliere die Nullhypothese.
Nullhypothese: Es gibt keinen Zusammenhang zwischen Bildung und Migrationswertschätzung.
Achtung: Wir haben hier auf eine kausale Formulierung der Hypothese verzichtet - hätten diese aber auch vornehmen können, wenn wir dazu bereit wären, die Kausalitätsfrage im weiteren Verlauf der empirischen Bearbeitung und Auswertung zu addressieren und zu problematisieren.
3. Erstelle einen Teildatensatz mit den Variablen cntry, eduyrs und imbgeco. Reduziere dann den Datensatz auf Merkmalsträger aus Deutschland. Filtere zum Schluss die NAs heraus.
ess8_ss <- select(ess8, cntry, eduyrs, imbgeco)
ess8_DE <- filter(ess8_ss, cntry == "DE")
ess8_DE <- na.omit(ess8_DE)
attributes(ess8_DE$imbgeco)## $label
## [1] "Immigration bad or good for country's economy"
##
## $format.stata
## [1] "%20.0g"
##
## $labels
## Bad for the economy 1 2
## 0 1 2
## 3 4 5
## 3 4 5
## 6 7 8
## 6 7 8
## 9 Good for the economy Refusal
## 9 10 NA
## Don't know No answer
## NA NA
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"attributes(ess8_DE$eduyrs)## $label
## [1] "Years of full-time education completed"
##
## $format.stata
## [1] "%12.0g"
##
## $labels
## Refusal Don't know No answer
## NA NA NA
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"summary(ess8_DE)## cntry eduyrs imbgeco
## Length:2814 Min. : 2.00 Min. : 0.000
## Class :character 1st Qu.:12.00 1st Qu.: 5.000
## Mode :character Median :14.00 Median : 6.000
## Mean :14.28 Mean : 5.829
## 3rd Qu.:16.00 3rd Qu.: 8.000
## Max. :28.00 Max. :10.000Die Teilstichprobe ohne NAs beinhaltet noch 2814 Fälle. eduyrs misst die Bildungsjahre eines Merkmalsträgers, imbgeco gibt auf einer Zehnerskala an, ob eine Person der Meinung ist, dass Migration schlecht (0) oder gut (10) für die Wirtschaft sei.
4. Berechne ein lineares Regressionsmodel und speichere dessen Output.
modell_DE <- lm(imbgeco ~ eduyrs, data = ess8_DE)5. Interpretiere den Regressionskoeffizienten und seinen Standardfehler sowohl technisch als auch inhaltlich.
summary(modell_DE)##
## Call:
## lm(formula = imbgeco ~ eduyrs, data = ess8_DE)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.3579 -1.3511 0.2015 1.6421 5.0964
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.23243 0.19277 21.956 <2e-16 ***
## eduyrs 0.11186 0.01316 8.504 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.306 on 2812 degrees of freedom
## Multiple R-squared: 0.02507, Adjusted R-squared: 0.02472
## F-statistic: 72.31 on 1 and 2812 DF, p-value: < 2.2e-16Regressionskoeffizient: Laut Regressionskoeffizienten (0.11) steigt mit jedem zusätzlichen Bildungsjahr die Migrationswertschätzung im Schnitt um 0.11 Skalenpunkte. Dies entspricht etwa 0.034 Standardeinheiten.
Standardfehler: Der Standardfehler für den Regressionskoeffizienten beträgt 0.013. Der Standardfehler zeigt die erwartbare Abweichung vom ermittelten Koeffizienten in der Stichprobe zum wahren Koeffzienten in der Grundgesamtheit. Er zeigt somit die Präzision des Koeffizienten an, die in dem vorliegenden Fall recht hoch ist.
6. Interpretiere den p-Wert inhaltlich und in Bezug auf statistische Signifikanz.
p-Wert: Der p-Wert im Deutschland-Modell beträgt \(p<2e-16\) (0.0000000000000002). Er zeigt an, wie wahrscheinlich der vorgefundene Stichprobenkoeffizient ist, wenn es in Wirklichkeit bzw. in der Grundgesamtheit keinen Zusammenhang zwischen UV und AV gibt - in diesem Fall ist das vorliegende Stichprobenergebnis sehr unwahrscheinlich unter der Annahme von H0. Dieser p-Wert verweist folglich auf einen hochsignifikanten Zusammenhang in der Stichprobe (auf einem Niveau von \(p<0,001\)), somit werden dem Koeffizienten drei *** hinzugefügt.
7. Bewerte nun die unter Aufgabe 2 aufgestellte Nullhypothese.
Wir können die Nullhypothese, dass in der Grundgesamtheit kein Zusammenhang zwischen den Bildungsjahren und der Migrationswertschätzung besteht, ablehnen. Hinweis: Wenn keine explizite Aussage zum Ablehnungsniveau formuliert wurde, gehen wir von einer Ablehnungsgrenze von p=0.05 aus.
II. Konfidenzintervall, -band und Vorhersageband
8. Welches Konfidenzintervall des Koeffizienten ist grösser: das 95%, das 99% oder das 99.9% - Intervall? Warum?
Wenn die Sicherheit, dass der wahre Wert enthalten ist, vergrössert werden soll, muss das Netz bzw. das Intervall vergrössert werden. Das 99.9% - Intervall ist somit das grösste.
9. Berechne das 95% und das 99% Konfidenzintervall des Koeffizienten.
confint(modell_DE, level = 0.95)## 2.5 % 97.5 %
## (Intercept) 3.85444759 4.6104108
## eduyrs 0.08607013 0.1376594Der wahre Koeffizient der Grundgesamtheit liegt mit 95% Sicherheit zwischen 0.086 und 0.138.
confint(modell_DE, level = 0.99)## 0.5 % 99.5 %
## (Intercept) 3.73555373 4.7293047
## eduyrs 0.07795644 0.1457731Der wahre Koeffizient der Grundgesamtheit liegt mit 99% Sicherheit zwischen 0.078 und 0.146.
10. Erstelle mittels ggplot() eine Visualisierung der Regressionsgeraden und des 95% Konfidenzbandes. Was wird durch diesen Bereich markiert?
plot <- ggplot(ess8_DE, aes(x = eduyrs, y = imbgeco))+
geom_jitter(alpha = 0.4)+
scale_x_continuous(breaks = seq(0, 28 , 2))+
scale_y_continuous(breaks = seq(0, 10 , 1)) +
geom_smooth(method = "lm", se = TRUE, color = "red", fill = "yellow")+
theme_bw()+
labs(title = "Jitter-Plot Bildung und Migrationswertschätzung",
y = "Migrationswertschätzung (0=schlecht, 10=gut)",
x = "Bildungsjahre",
caption = "ESS(2016), Teilstichprobe DE, N=2814")
plot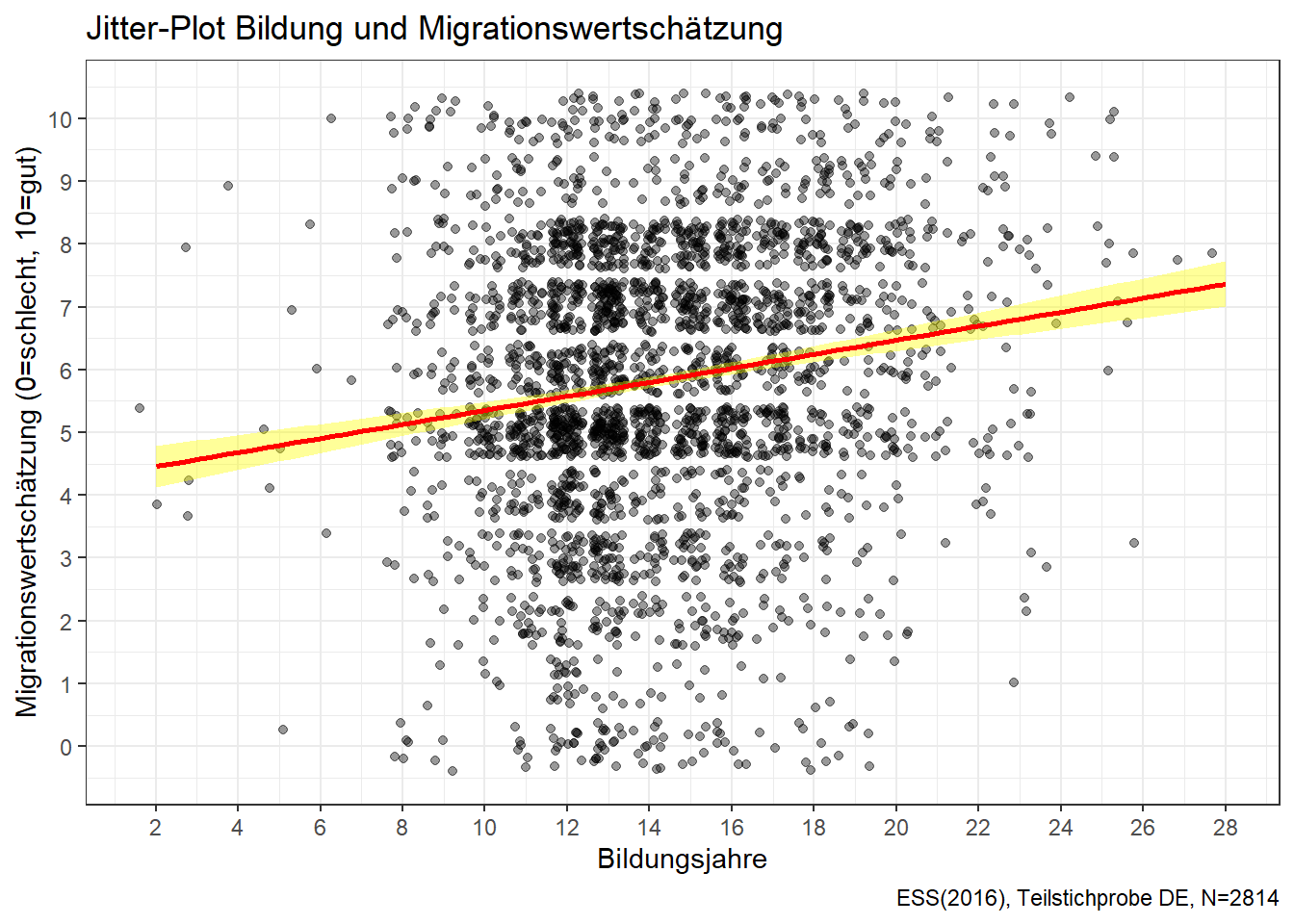
Das Konfidenzband zeigt den Bereich an, in dem die wahren Vorhersagewerte der Grundgesamtheit mit 95%-Sicherheit liegen. Es wird durch das Argument se = TRUE erzeugt.
11. Berechne das 95% Konfidenzintervall des Vorhersagewertes für eine Person mit obligatorischem Schulabschluss und anschliessender Berufslehre (12 Bildungsjahre). Interpretiere die Werte.
ggpredict(modell_DE, terms = "eduyrs[12]")## # Predicted values of Immigration bad or good for country's economy
##
## eduyrs | Predicted | 95% CI
## ---------------------------------
## 12 | 5.57 | [5.47, 5.68]Der Befehl zeigt den Vorhersagewert für eine Person mit 12 Bildungsjahren aufgrund unserer Regressionsanalyse an. Vorhergesagt wird ein Wert von 5.57 auf der Migrationseinstellungsskala. Ausserdem werden die Intervallsgrenzen angezeigt; der wahre Vorhersagewert für eine Person mit 12 Bildungsjahren liegt mit 95% Sicherheit zwischen 5.47 und 5.68.
12. Berechne nun das 50% Vorhersageintervall für eine Person mit 12 Bildungsjahren. Interpretiere die Werte.
ggpredict(modell_DE, terms = "eduyrs [12]", interval = "prediction", ci.lvl = 0.50)## # Predicted values of Immigration bad or good for country's economy
##
## eduyrs | Predicted | 50% CI
## ---------------------------------
## 12 | 5.57 | [4.02, 7.13]Der realisierte Einstellungswert bezüglich Migration einer Person mit 12 Bildungsjahren liegt mit 50% Sicherheit zwischen 4.02 und 7.13.
13. Lasst euch zum Schluss das 50% Vorhersageband auf eurem Plot anzeigen.
predictions <- predict(modell_DE, interval = "prediction", level = 0.50)Die Predictions werden zuerst in einem Objekt abgespeichert. Das Argument level wird, entsprechend der gewünschten Breite des Vorhersagebandes, auf 0.50 gesetzt. Andere Breiten wären auch natürlich auch möglich!
ess8_DE <- cbind(ess8_DE, predictions)Die Predictions werden mit dem ess8_DE-Teildatensatz kombiniert.
plot +
geom_line(aes(y = upr), color = "orange", linetype = "solid", data = ess8_DE)+
geom_line(aes(y = lwr), color = "orange", linetype = "solid", data = ess8_DE) 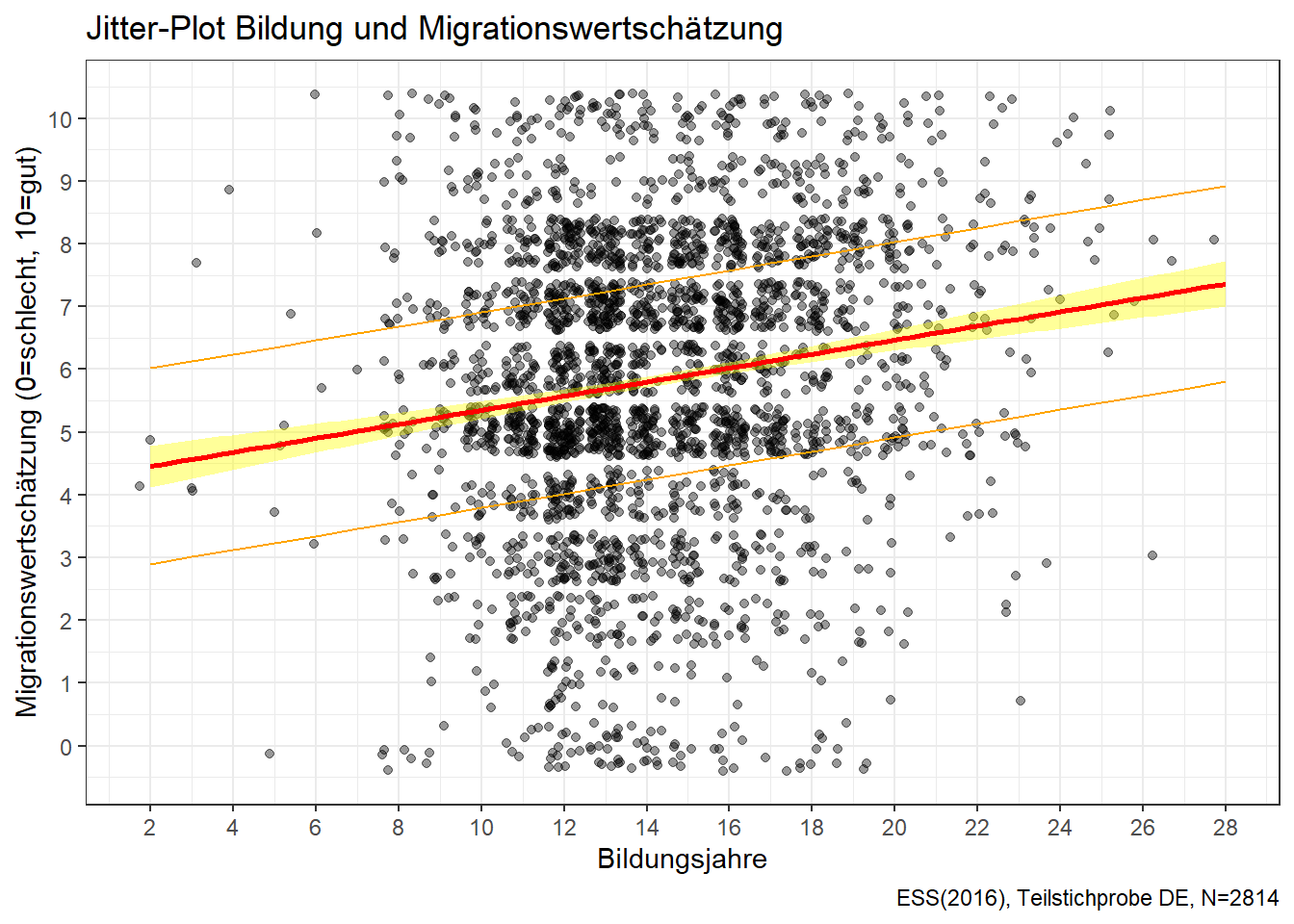
14. Was ist der Unterschied zwischen einem Konfidenz- und Vorhersageband und einem Konfidenz- und Vorhersageintervall?
Das Konfidenzband und das Vorhersageband können grafisch dargestellt werden, weil sie sich auf die ganze Regression beziehen. Das Konfidenzintervall des Vorhersagewertes und das Vorhersageintervall beziehen sich auf einen bestimmten Punkt auf der Regressionsgerade und zeigen die Breite des jeweiligen Bandes für diesen spezifischen Punkt an.
Zusammenfassend:
95% Konfidenzintervall des Koeffizienten: “Der wahre Koeffizient der Grundgesamtheit liegt mit 95% Sicherheit zwischen 0.086 und 0.138”.
confint(modell_DE, level = 0.95)95% Konfidenzband: Grafisch
Das Konfidenzband zeigt den Bereich an, in dem die wahren Vorhersagewerte der Grundgesamtheit mit 95% Sicherheit liegen.
se = TRUE95% Konfidenzintervall der Vorhersagewerte: Ein Querschnitt aus dem Konfidenzband bei einem bestimmten x-Wert: “Der Vorhersagewert für eine Person mit 12 Bildungsjahren liegt in der Grundgesamtheit mit 95% Sicherheit zwischen 5.45 und 5.68”.
ggpredict(modell_DE, terms = “eduyrs[12]”)50% Vorhersageband: Grafisch
Das Vorhersageband zeigt den Bereich an, in dem die tatsächlichen Werte mit 50-prozentiger Sicherheit liegen.
predictions <- predict(modell_DE, interval = “prediction”, level = 0.50) ess8_DE <- cbind(ess8_DE, predictions)
plot + geom_line(aes(y = upr), color = “orange”, linetype = “solid”, data = ess8_DE)+ geom_line(aes(y = lwr), color = “orange”, linetype = “solid”, data = ess8_DE)50%* Vorhersageintervall: Ein Querschnitt aus dem Vorhersageband bei einem bestimmten x-Wert: “Der tatsächliche Einstellungswert für eine Person mit 12 Bildungsjahren liegt mit 50% Sicherheit zwischen 4.02 und 7.13”.
ggpredict(modell_DE, terms = “eduyrs [12]”, interval = “prediction”, ci.lvl = 0.50)